
AI is no longer a buzzword reserved for tech giants, it’s becoming part of everyday tools. One exciting example is Whisper AI, an open-source speech recognition model developed by OpenAI. Whisper can take your audio recordings and turn them into text with impressive accuracy. Whether you’re a student transcribing lectures, a content creator turning podcasts into blogs, or just curious about AI, running Whisper on your own machine unlocks a world of possibilities.
Here’s today’s slight insight on Running Whisper AI on your own machine.
System Requirements & Prerequisites
Before we jump into installation, let’s make sure your system is ready. Whisper is lightweight compared to some AI models, but smooth performance still depends on your setup.
| Requirement | Recommended Spec |
|---|---|
| Operating System | Windows 10/11, macOS, or Linux |
| Processor (CPU) | Quad-core or better |
| Memory (RAM) | At least 8GB (16GB+ preferred) |
| GPU (optional) | NVIDIA GPU with CUDA for faster processing |
| Python Version | 3.8 or later |
Installing Whisper AI and Its Components
To run Whisper, you’ll need to install a few things.
| Step | Tool | Purpose |
|---|---|---|
| 1 | Python | Base programming language |
| 2 | PyTorch | Machine learning framework used by Whisper |
| 3 | Chocolatey | Package manager (Windows) for easier installs |
| 4 | FFmpeg | Handles audio/video formats |
| 5 | Whisper AI | The speech recognition model itself |
Install Python
The first step, if you don’t have it already, is to install a version of Python on your computer. Python serves as the foundation for running Whisper, as the model is built using PyTorch and requires Python 3.8 or newer.
- Download from python.org.
- During Windows installation, make sure to check “Add Python to PATH”
- Verify python version installed on your system with below command
python –version
Install PyTorch
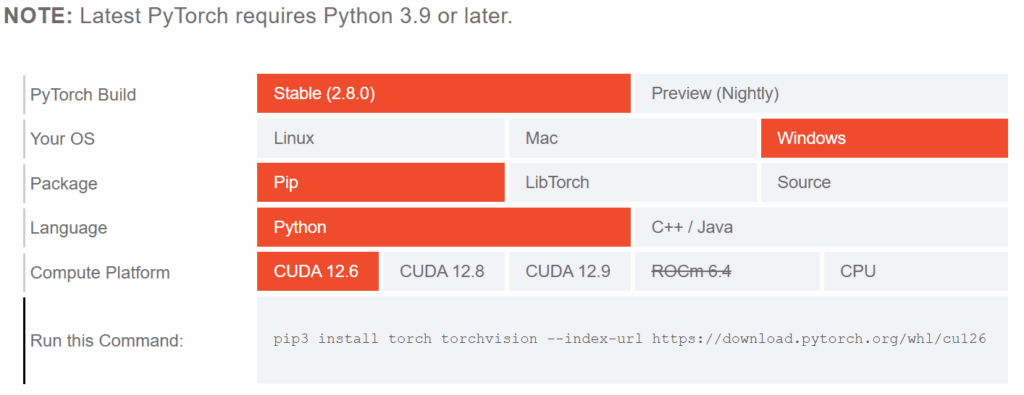
Now we can install the PyTorch library, which is the machine-learning framework that powers Whisper’s neural networks. PyTorch requires specific configuration based on your system, so we’ll use their interactive installation guide.
Go to the PyTorch website and copy the install command matching your setup (CPU or GPU).
- Command:
- pip3 install torch torchvision –index-url https://download.pytorch.org/whl/cu126
Install Package Manager
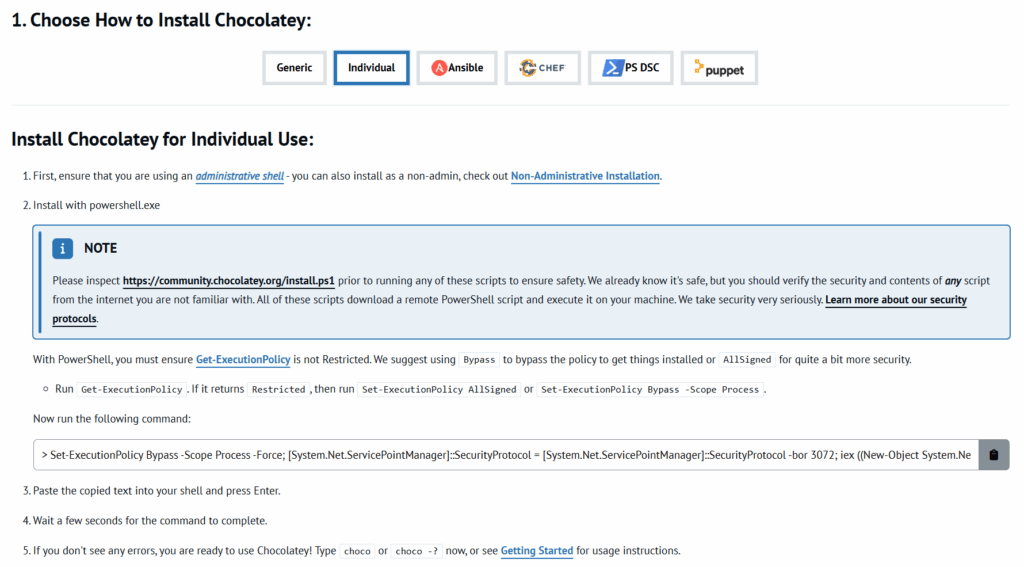
Before we can install FFmpeg, Windows users need a package manager.
Visit chocolatey.org Click the “Install” tab in the top right corner Choose “Individual” use Open PowerShell as Administrator:
- Type “PowerShell” in your computer’s search bar
- Select “Windows PowerShell”
- Click “Run as Administrator”
- Copy the installation command from Chocolatey’s website Paste into PowerShell and press Enter
- Set-ExecutionPolicy Bypass -Scope Process -Force; [System.Net.ServicePointManager]::SecurityProtocol = [System.Net.ServicePointManager]::SecurityProtocol -bor 3072; iex ((New-Object System.Net.WebClient).DownloadString(‘https://community.chocolatey.org/install.ps1’))
Install FFmpeg
This library converts between different audio formats, processes audio streams, and handles the technical aspects of reading your media files so Whisper can focus on transcription.
- on Ubuntu or Debian
- sudo apt update && sudo apt install ffmpeg
- on Arch Linux
- sudo pacman -S ffmpeg
- on MacOS using Homebrew (https://brew.sh/)
- brew install ffmpeg
- on Windows using Chocolatey (https://chocolatey.org/)
- choco install ffmpeg
- on Windows using Scoop (https://scoop.sh/)
- scoop install ffmpeg
Install Whisper AI
You’re now ready to install Whisper itself! This final step brings everything together.
pip install -U openai-whisper
Alternatively, the following command will pull and install the latest commit from this repository, along with its Python dependencies:
pip install git+https://github.com/openai/whisper.git
Whisper comes with several model sizes, each offering different trade-offs between accuracy and speed:
| Size | Parameters | English-only model | Multilingual model | Required VRAM | Relative speed |
|---|---|---|---|---|---|
| tiny | 39 M | tiny.en | tiny | ~1 GB | ~10x |
| base | 74 M | base.en | base | ~1 GB | ~7x |
| small | 244 M | small.en | small | ~2 GB | ~4x |
| medium | 769 M | medium.en | medium | ~5 GB | ~2x |
| large | 1550 M | N/A | large | ~10 GB | 1x |
| turbo | 809 M | N/A | turbo | ~6 GB | ~8x |
The first time you run Whisper, it will automatically download your chosen model. This process might take several minutes depending on your internet connection, but subsequent uses will be much faster.
Using Whisper AI
Now comes the exciting part, using Whisper to transcribe your audio files. The beauty of Whisper lies in its simplicity; you can start with basic commands and gradually explore more sophisticated features as your needs grow.
Commandline usage
whisper audio.mp3 –model small
audio.mp3→ your input file.--model small→ choose the model size (tiny, base, small, medium, large).
Python usage
Transcription can also be performed within Python
import whisper
model = whisper.load_model("turbo")
result = model.transcribe("audio.mp3")
print(result["text"])Whisper supports multiple output formats, each serving different purposes:
- TXT: Plain text transcription
- VTT: Video subtitles with timestamps
- SRT: Standard subtitle format
- JSON: Detailed output with confidence scores and timing
Conclusion
Setting up Whisper AI may sound technical at first, but it’s just a matter of stacking the right tools: Python, PyTorch, Chocolatey, FFmpeg, and Whisper itself. Once installed, you have a powerful transcription tool running locally on your computer. Whisper puts you in control of your data while giving you enterprise-grade AI right at home.
Whether you’re a student, content creator, or developer, Whisper can save hours of manual transcription and unlock new productivity workflows.
Frequently Asked Questions
Can Whisper run without an internet connection?
Yes, once installed and the models are downloaded, Whisper runs completely offline. You only need internet for the initial installation and model downloads.
How accurate is Whisper compared to other transcription services?
Whisper typically achieves 85-95% accuracy on clear audio, which is comparable to premium services like Rev or Otter.ai, especially with the larger models.
What audio formats does Whisper support?
Whisper supports most common audio formats including MP3, WAV, MP4, M4A, FLAC, and OGG. It automatically converts formats using FFmpeg.
Can I transcribe audio in languages other than English?
Yes, Whisper supports 99+ languages. You can specify the language with the --language parameter for better accuracy, or let it auto-detect.
Is GPU acceleration worth it for Whisper?
GPU acceleration can provide 5-10x speed improvements, especially with larger models. However, Whisper works fine on CPU-only systems, just slower.




Leave a Reply
You must be logged in to post a comment.